Quantifying the Notion of Bias in Face Inference Models

- Posted by ostadabbas
- Posted in Research
Overview:
In this research, we present a general pipeline to interpret the internal representation of face-centric inference models. Our pipeline is inspired by the Network Dissection, which is a popular model interpretability pipeline that is explicitly designed to interpret object-centric and scene-centric tasks. Similar to the Network Dissection approach, our interpretability pipeline has two main components: (i) a visual Face Dictionary, composed of a collection of facial concepts along with images of the concepts, and (ii) an algorithm that pairs network units with the facial concepts. With the proposed pipeline, we first conduct two controlled experiments on biased data to show the effectiveness of the pipeline. In particular, the controlled experiments illustrate how the face interpretability pipeline can be used to discover bias in the training data. Then, we dissect different face-centric inference models trained on widely used facial datasets. Our dissection results show that models trained for different tasks have different internal representations. Furthermore, the interpretability results also reveal some bias in the training data and some interesting characteristics of the face-centric inference tasks.
Code:
Here is the link to our github code. The Face Dictionary and models can be found here.
Face Dictionary:
Our Face Dictionary is the first facial dataset that has binary segmentation labels for a wide range of local facial concepts belonging to three major types: (1) Action Units, (2) Facial Parts, and (3) Facial Attributes. Our dictionary also contains non-local concepts, i.e., concepts that cannot be localized in specific areas or parts of the face, such as the age, the gender, the ethnicity, and the skin tone.

There are several datasets that provide labels for action units and facial attributes merely indicating whether a particular attribute or action unit is present in a given image, without providing the corresponding location in the image. However, our dictionary needs the segmentation of the local concepts to be used during the concept-unit pairing. For this reason, we have assembled our Face Dictionary dataset by estimating the regions for these concepts using facial landmarks. Our dictionary consists of images taken from the EmotioNet and CelebA datasets. We run a landmark detection algorithm on our chosen images as we use the landmarks to estimate the region where our local concepts lie. We estimate the center and covariance matrix of a 2D Gaussian confidence ellipse around a particular concept and generate a binary mask for each concept per image as seen below.

Network Dissection:
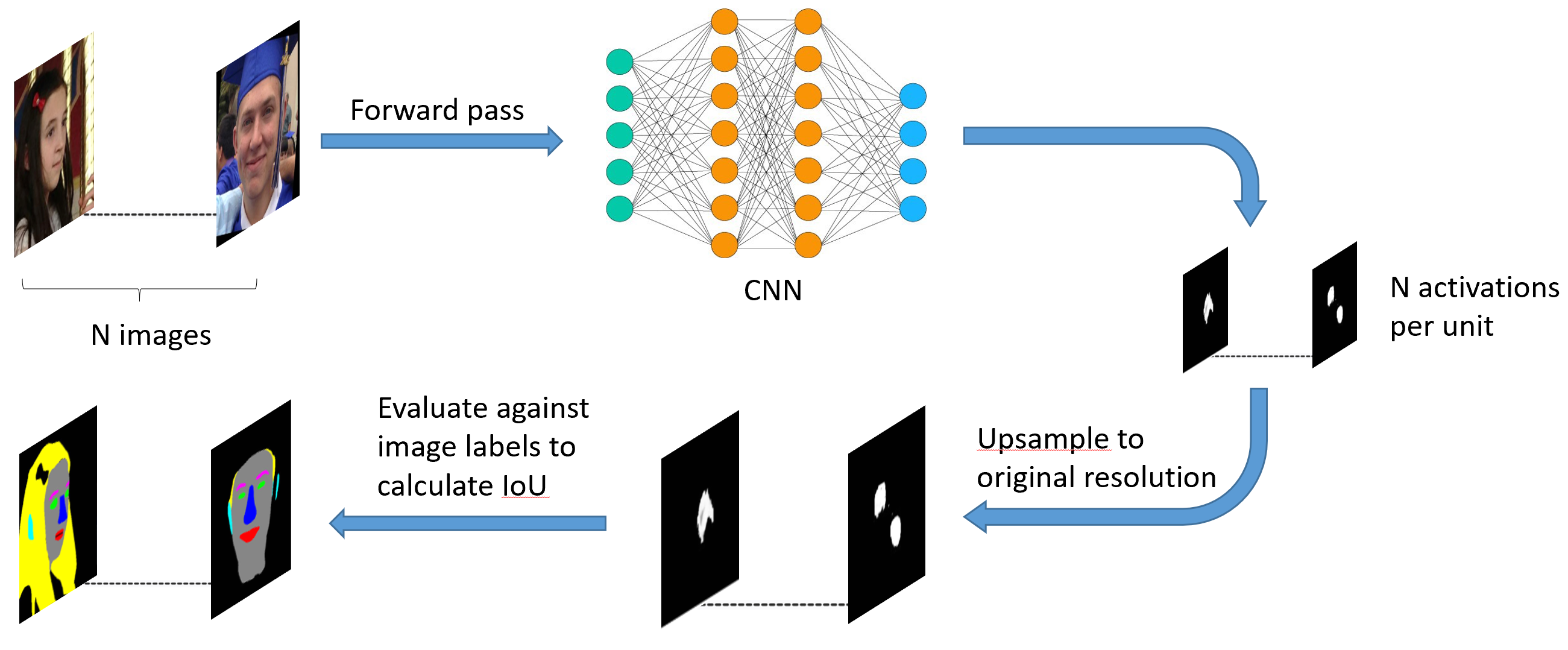
Network Dissection is a general framework for quantifying the interpretability of the hidden units in any convolutional layer of a neural network trained for an object-centric or a scene-centric task. Unlike the original work where it is extremely unlikely for two concepts to have labels with spatial overlap, our dictionary has multiple instances of such concepts that lie in a similar region of the face. Hence, we take a forward pass across all the images in our dictionary to store their activation maps and run network dissection to identify the concept with the best IoU for each unit using a unit-concept pairing formulation explained in detail in the paper.

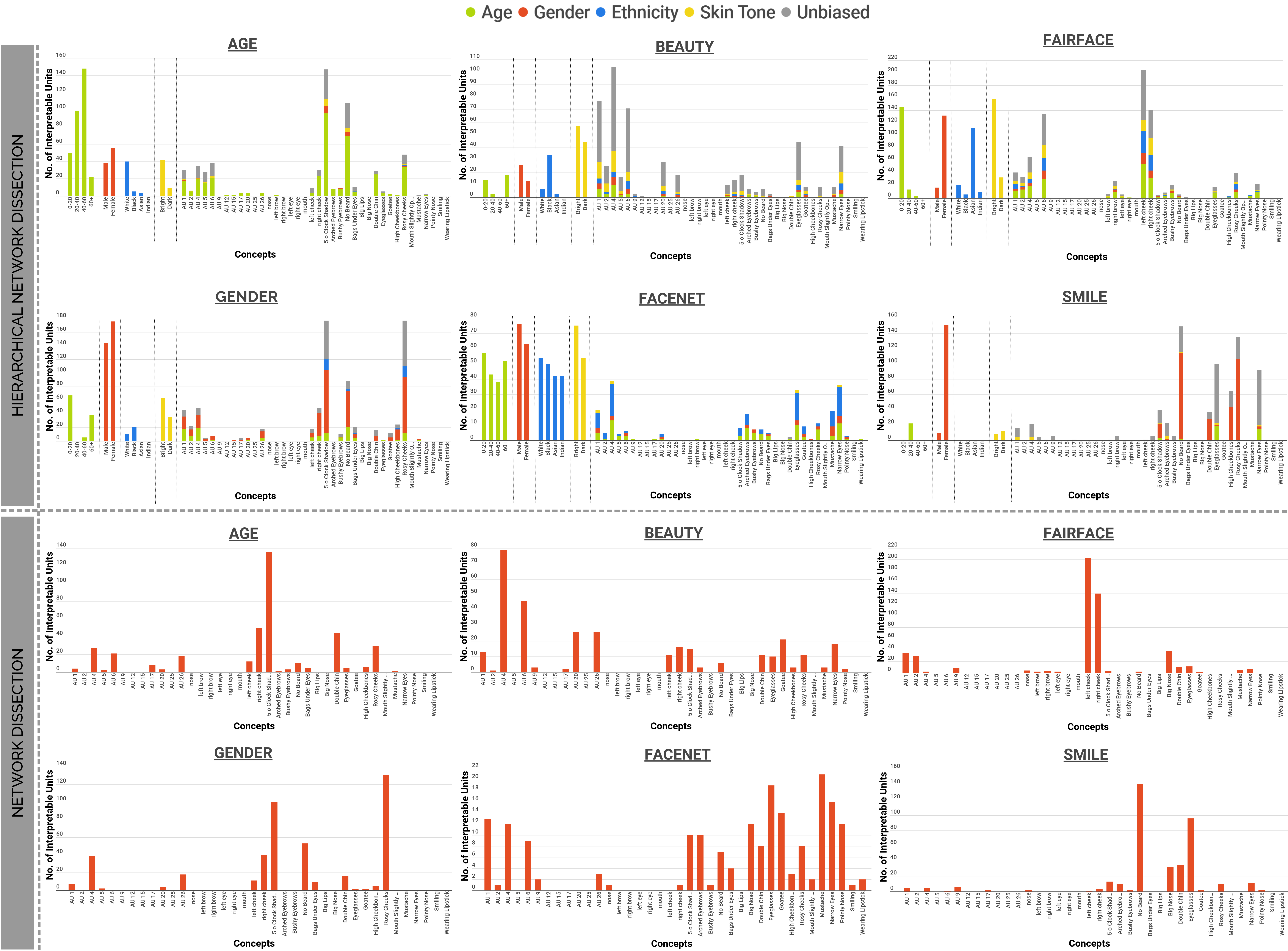
After identifying the best concept per unit using the IoU scores, we use our own probabilistic formulation to establish a hierarchy among all the concepts that lie in the similar region of the face. This is done to determine whether a given unit is conceptually discriminative or if it only has the ability to differentiate among different regions of the face and not the higher level local concepts. Below we have a list of all the face inference models that have been dissected and their respective performance on the datasets used to train them.
n, khv kh

What we learn:
Dissection Results
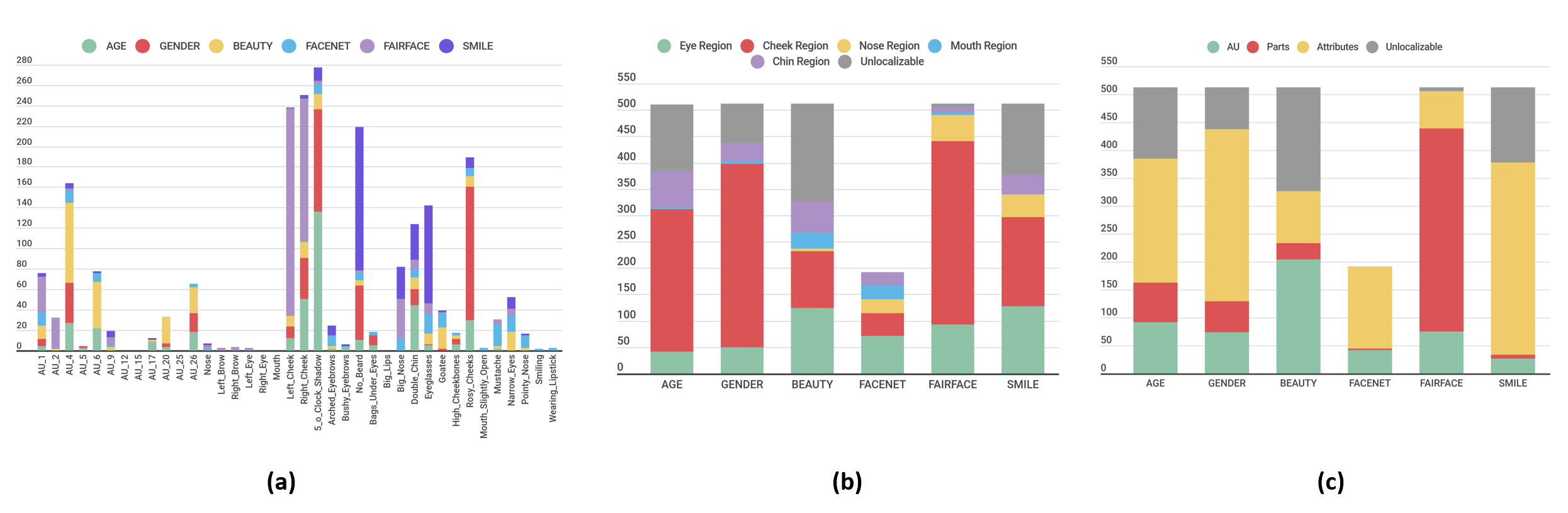
Dissecting these networks allows us to look at the representations learned by these models and determine whether or not certain neurons are capable of detecting higher level concepts with a high level of certainty. We observe that there are several units that behave as detectors for a lot of the concepts that we introduce in the Face Dictionary. We learn about the different types of concepts each model focuses on as displayed in the figures below and gain some insight about the differences in the representations learned by the same architecture for different tasks. These findings also point to the biases that exist in the datasets that are used to train these models.


Simulated Experiments
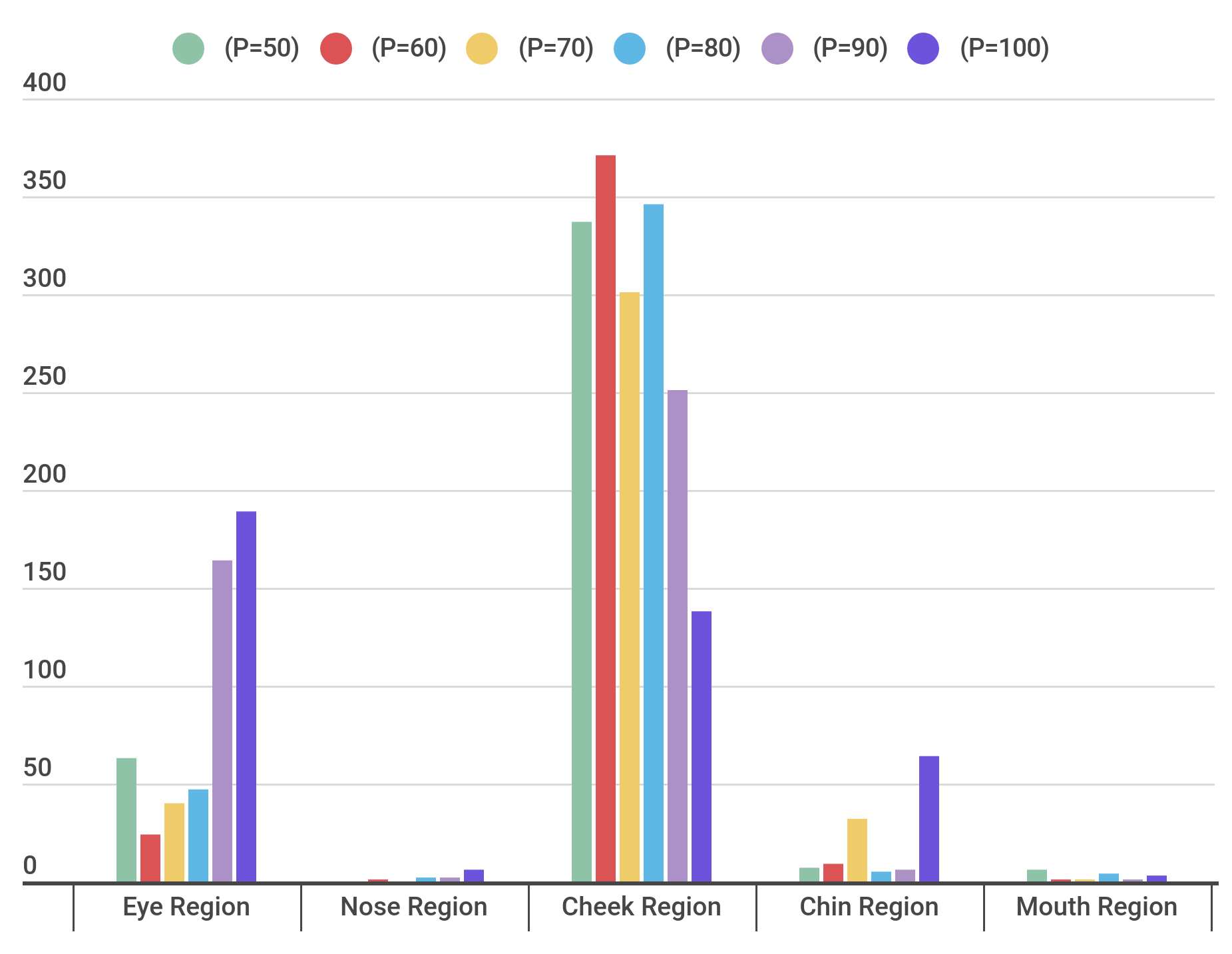
We also use two simulated experiments to showcase the ability of our pipeline to uncover biases in the training data. We choose eyeglasses as the local concept and create 6 versions of the training set for a gender classifier with 6 different P values (P=50,60,70,80,90,100) where P indicates the percentage of males having eyeglasses and 1-P indicates the percentage of females having eyeglasses. We observe that dissecting these models showcases a higher number of detectors in the Eye Region as the P value increases as shown below which vindicates the use of this formulation.

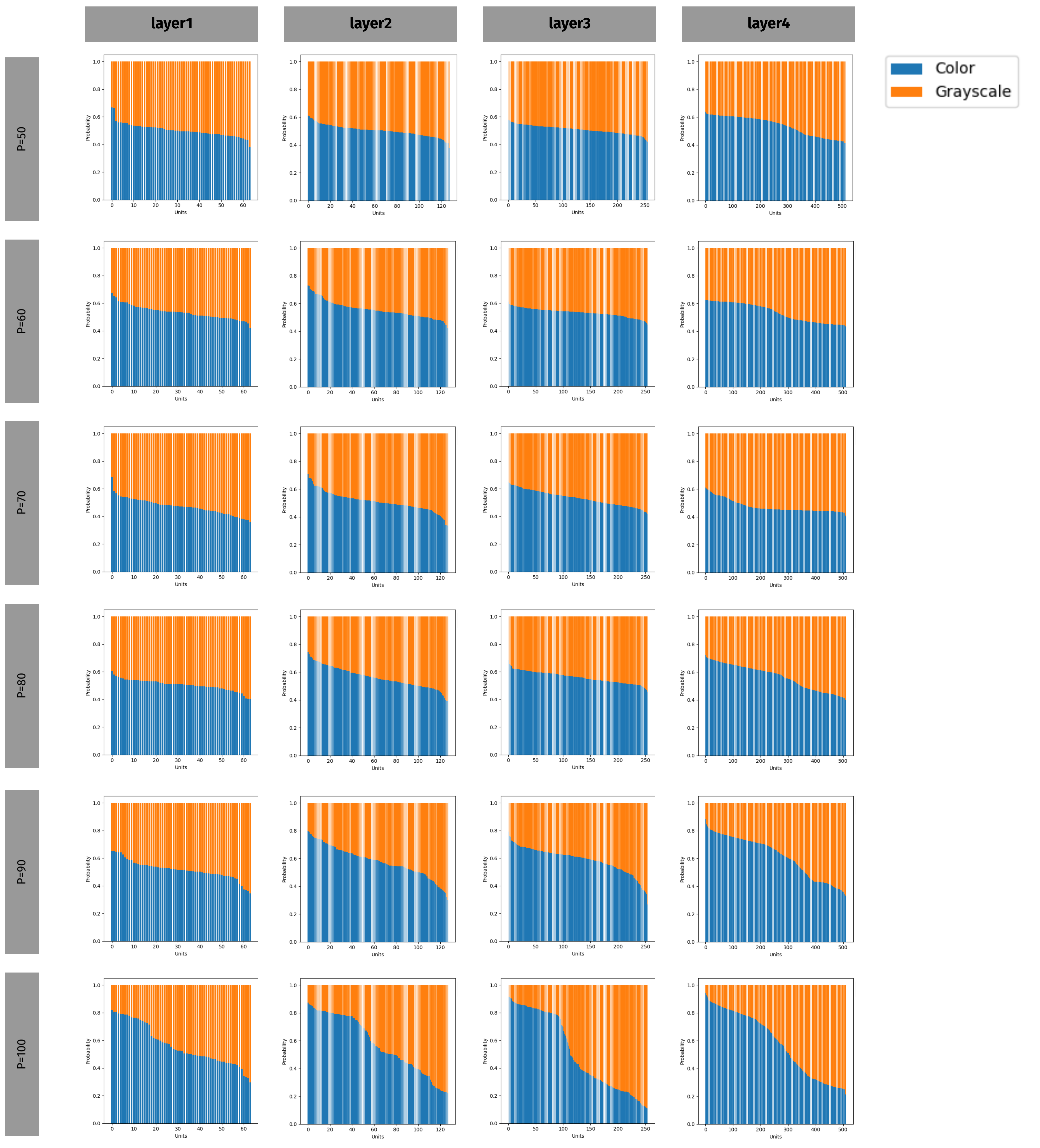
For the second experiment, we choose grayscale as the non local concept for a similar gender classifier with the exact same P values. Only this time P value shows how many images are grayscale amongst males and females. In this experiment we aim to see more and more biased units as P value increases because understanding the differences between color and grayscale relates to better gender classification. As we can see below, we observe more and more biased units as P goes from 50 to 100 for all 4 blocks of the ResNet-50 architecture and the slope of the graph becomes steeper.

Related Work:
- David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations.
- David Bau, Jun-Yan Zhu, Hendrik Strobelt, Agata Lapedriza, Bolei Zhou, and Antonio Torralba. Understanding the role of individual units in a deep neural network.
- David Bau, Jun-Yan Zhu, Hendrik Strobelt, Bolei Zhou, Joshua B Tenenbaum, William T Freeman, and Antonio Torralba. Gan dissection: Visualizing and understanding generative adversarial networks.
- Aravindh Mahendran and Andrea Vedaldi. Understanding deep image representations by inverting them.
- Brandon Richard Webster, So Yon Kwon, Christopher Clarizio, Samuel E Anthony, and Walter J Scheirer. Visual psychophysics for making face recognition algorithms more explainable.
- Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps.
- Zeyu Wang, Klint Qinami, Ioannis Christos Karakozis, Kyle Genova, Prem Nair, Kenji Hata, and Olga Russakovsky. Towards fairness in visual recognition: Effective strategies for bias mitigation.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}