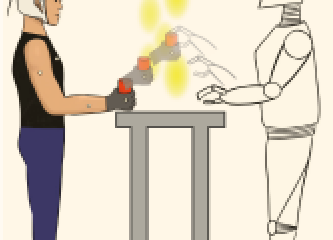
We represent the state of the world in a low-dimensional subspace, called “pose”, which is a succinct interpretable representation of important information in the state. The state can then be estimated and predicted from this low-dimensional representation. The pose can also be used as a semi-supervised generative model to render and expand the labelled examples in the state space for the purpose of data augmentation for deep learning algorithms.
At Augmented Cognition Lab (ACLab), currently we work on three active projects, in which they explore different aspects of pose estimations (the cited papers are available at ACLab webpage alongside their datasets/codes):
(1) Articulated/Deformable Body Pose Estimation:
- “Inner Space Preserving Generative Pose Machine,” ECCV 2018.
- “A Semi-Supervised Data Augmentation Approach using 3D Graphical Engines,” ECCV/HBU 2018.
- “Moving Object Detection through Robust Matrix Completion Augmented with Objectness,” J-STSP 2018.
- “In-Bed Pose Estimation: Deep Learning with Shallow Dataset,” arXiv preprint 2018.
- “A Vision-Based System for In-Bed Posture Tracking,” ICCV/ACVR 2017.
- “Long-Term Non-Contact Tracking of Caged Rodents,” ICASSP 2017.
(2) Affective Pose Estimation:
- “Facial Expression and Peripheral Physiology Fusion to Decode Individualized Affective Experience,” IJCAI/AffCom 2018.
- “The Emotional Voices Database: Towards Controlling the Emotion Dimension in Voice Generation Systems,” arXiv preprint 2018.
- “Decoding Emotional Experiences through Physiological Signal Processing,” ICASSP 2017.
(3) Environment Pose and Scene Understanding:
- “First-Person Indoor Navigation via Vision-Inertial Data Fusion,” IEEE/ION PLANS 2018.
- “Background Subtraction via Fast Robust Matrix Completion,” ICCV/RSL-CV 2018.
Funding: National Science Foundation (NSF), MathWorks, Amazon Web Services (AWS), INVIDIA.